Tailored Solutions for Enhanced Security and Operational Efficiency
Problem Statement
Count the number of people passing through the gate with help of CCTV footage
Initial data provided
Data Contains
Images
Data format
Jpg, Png
Shade Card
pdf
Inference Labs Approach
Input Data:
Load Images of different format using Computer Vision.
We require a minimum of 300 images for each shade or based on bottle size. These images should be clear and captured from a top angle.
In cases where the size of bottles/packaging varies, as depicted in the image on the right side, clarity on shades is compromised. Therefore, we need additional images that provide a clearer understanding of the shades in such scenarios.
3. Data Tagging
Create separate classes for each object present in the input images. Subsequently, meticulously label each object in the images using any annotation tool through manual annotation.
Data Preprocessing:
We need to perform typical preprocessing tasks such as normalization, scaling, greyscaling, and morphology (smoothening edges).
Additionally, data augmentation should be applied if the dataset is not balanced.
Model Building:
Object detection: In our quest for accurate identification of both color and quantity within the product stock, we aim to employ the sophisticated technique of object detection. This entails training a specialized model capable of recognizing and precisely locating multiple objects within an image. To achieve this, we are considering state-of-the-art models for this task. Which can be.
Quick and efficient, especially good for situations where we need fast and accurate results.
Very good at finding and understanding different things in pictures with high precision.
Fast and balanced, perfect for quickly figuring out what’s in a picture without compromising its accuracy.
Effort Required: The annotations should include details regarding colors/shades and quantities, ensuring the model is trained on a comprehensive and representative dataset. Multiple models need to be trained based on accuracy standards and an A100 or v100 GPU machine will be used.
Precision and Recall check:
We need to assess the performance of both classification and localization using bounding boxes in the images.
Precision and Recall will serve as the metrics to evaluate performance. These metrics are calculated based on true positives (TP), false positives (FP), and false negatives (FN)
Hyper parameter tuning:
Hyperparameter optimization or tuning involves selecting an optimal set of hyperparameters for a learning algorithm. A hyperparameter is a parameter whose value controls the learning process.
It is necessary to retrain the model by tuning the hyperparameters to achieve better accuracy.
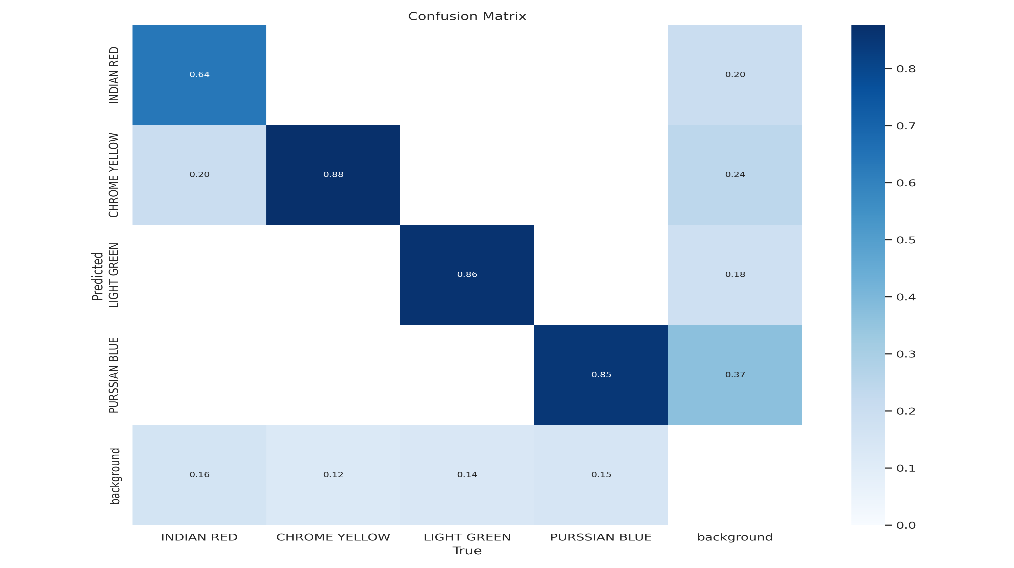
Sample Metric:
Final Testing:
We need to test our model on the test data and evaluate precision and recall. If the accuracy falls below the desired level, we should retrain the model by tuning the hyperparameters.
Below are the sample output examples:
sample outputs only taken 3-4 colors (yellow, green, red, and blue) into consideration.
Limitation: If images overlap or are placed on shelves, it increases the complexity of color detection.
Challenge: Overlapping may lead to confusion in distinguishing individual products and accurate color identification.
Partially Visible Objects:
Limitation: If objects in the images are only partially visible (less than 30-40%), there is a risk of detection failure.
Challenge: Partial visibility reduces the amount of information available for accurate color recognition, potentially leading to detection errors.
Overlapping Content:
Limitation: Overlapping content in images may result in a double count of products.
Challenge: The system may struggle to differentiate between individual products when they are closely packed or overlap, impacting accuracy in counting.
Similar Shades:
Limitation: If shades are very similar, the accuracy of color detection decreases.
Challenge: The system may struggle to distinguish subtle differences in closely related shades, potentially leading to misclassifications.
Limited Clarity for Large Bottles:
Limitation: If the size of the bottles is large as mentioned in the input data the shades are not clear
Challenge: Images containing large bottles may require additional clarity for shades, suggesting the need for a specialized dataset or imaging setup to capture details more effectively.
Image Clarity and Angle:
Limitation: Images lacking clarity or captured from suboptimal angles may affect color recognition.
Challenge: Ensuring that all images in the dataset are clear and captured from top angles is crucial for the model to accurately identify shades.
Additional Consideration: In the case of shades like pearl, glitter, regular, and pearl metallic shades, it is imperative that the shades are distinct and identical.
Otherwise, accuracy may be compromised, and the model might fail to identify subtle differences.
Expected Output Format:
Output result
Detected objects image, Json with number of counts of objects in image.
Output format
Jpg, png, jpeg
Unlock the Power of Feedback with Inference Labs Today!