Video consumption is increasing leaps and bounds with abundant devices for streaming videos every second. We cannot fathom a single day where we are not watching at least one single video from top streaming platforms such as Youtube, Netflix, etc.
There is a vast amount of research being done in the video domain with a multitude of applications be it for retail, media, surveillance, and the list goes on. For businesses looking to tap into these vast sources of information, the insights captured by these videos cater to the different styles of needs one can imagine. One of the long-known applications in the video domain is action recognition and detection. In this post, we are going to understand more about action recognition and how anyone with decent python experience can start fiddling with the humongous video data sources.
The main task in activity recognition is to identify the type of activity being performed in a video clip. Often there will be some actors who are performing some actions which can be either scripted (for a specific industry or academic requirement) or unscripted (people following usual chores without adhering to a particular order of actions). There are a few common features that separate different video activity datasets, such as —
-
Camera View — Is it a single view or a multi-view camera setting?
-
Camera Framing — Does the dataset have high or low camera framing?
-
Activity Variation — Do the activities have high temporal variation?
-
Number of Activities — How many different activities are present?
-
Category of Activities — Are the activities related to different genres or are these related to a specific genre such as sports, cooking, etc.
The above features are not exclusive but do capture a general type of video datasets. In a constrained environment (which is true for most of the datasets), there might be only a single view or multiple views of the same activity instance. The activities performed can be either centrally located in the camera frame or it can be varying across different frame locations (which includes some form of occlusions as well). If the video dataset offers a wide variety of activities, it is possible to have a different style of the same activities performed by the same or different actors. Even video datasets can be captured using a handheld or some wearable devices to give an egocentric view of activities. These egocentric views capture the human gaze while performing the activities and hence can further analyze the understanding of human behavior towards an action. One of the largest egocentric datasets available is named EPIC-Kitchens containing 55 hours of video data. List of other video datasets and their features are briefly described in https://www.di.ens.fr/~miech/datasetviz/.
Here, we will be looking at the functionalities offered by the PyTorch framework for activity recognition. In the computer vision, literature action and activity are often used interchangeably, but there might be some disputes on that. PyTorch offers 3 action recognition datasets — Kinetics400 (with 400 action classes), HMDB51 (with 51 action classes) and UCF101 (with 101 action classes). Kinetics is a popular action recognition dataset and used heavily as a pre-training dataset for most of the action recognition architectures. For this post, we will look at the HMDB51 dataset and see how one can quickly spin up pre-trained CNN architectures for action recognition.
HMDB51 dataset was published in 2011 and contains 51 action categories with a minimum of 101 video clips for each action. Some of the actions present in the HMDB51 are shown. Refer to the website for more details.
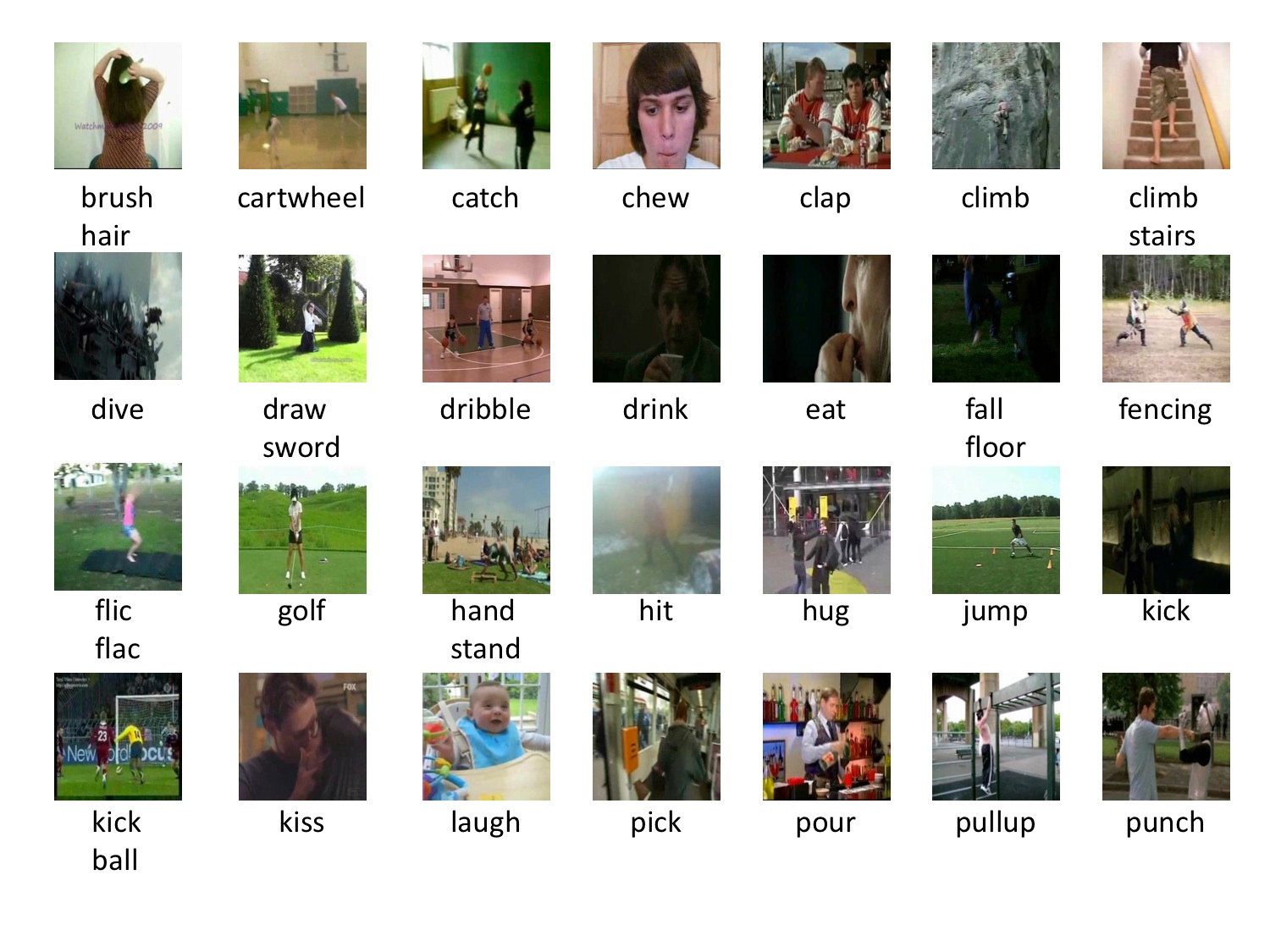
As you can see from the HMDB51 sample, the dataset has high camera viewpoint variation and possess both low and high camera framing instances. Let us see how we can use PyTorch capabilities to work with the HMDB51 dataset.
One should be familiar with convolution layers (ideally 3D, but it is just an extension of 2D), how videos are processed by a convolution layer and a general understanding of how deep learning neural nets work. The entire notebook is available as a Google Colab Notebook. Feel free to copy and start fiddling with your experiments.
First, we have to install some dependencies in the Colab. Video datasets in PyTorch require a module named PyAV. This module is a python binding for FFmpeg libraries (needed for extracting frames from video clips). It’s not straightforward to install it as it involves a lot of dependencies, but the below steps worked for me and it might work for others as well.

Post that, we download the dataset and the train test splits required for training deep neural net. The standard splits should be followed to compare your results with others universally.

Load up the required libraries to work with video datasets and PyTorch framework. Colab comes loaded with almost all the common deep learning frameworks and should be straight forward to use.
The HMDB51 rar files need to be extracted into a folder with sub-folders containing instances of a single action. The code below extracts and organizes the clips into their respective action class. This displays extraction logs of all the individual rar files of the actions.
To work with deep neural nets for model training and testing, it is a standard to apply some form of transformation to the input such as scaling, flipping, etc. Transformations are needed for various purposes such as to include variations in the dataset for robustness, to increase training data size, normalizing a new dataset using mean and variance and so on. We will use a predefined transformation file present in the PyTorch library for video datasets.

Now we define a simple deep neural net Res3D_18 for action recognition. PyTorch provides 3D ResNet with 18 parametric layers out of a total of 3 architectures for video data. All of these deep neural nets are pre-trained on the Kinetics400 dataset and so support Transfer Learning for fine-tuning other similar video datasets. Start by defining a PyTorch model class and modify the Res3D_18 architecture to include 51 classes of HMDB51 dataset.
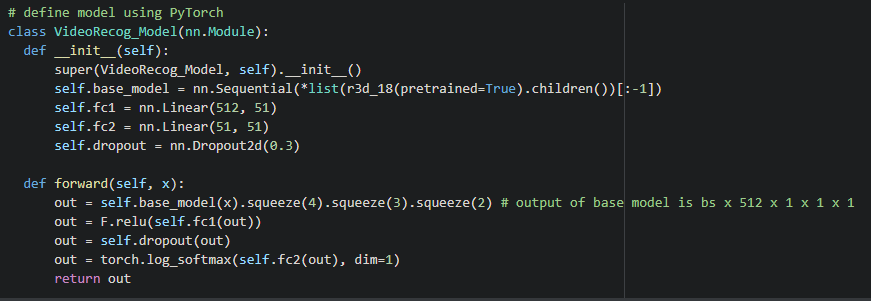
The above architecture only adds a simple Dense layer with 51 output nodes for action recognition. There are other advanced architectures than this such as C3D, I3D, etc. But for the purpose of this post, one can simply use Res3D_18 architecture to get comfortable with the whole process before moving on to the advanced stuff. In most of the research papers about video datasets, the base architecture for feature extraction is either I3D or C3Dand they provide much better video features for desired downstream tasks such as activity recognition and detection.
So far we haven’t discussed the HMDB51 dataset module provided by PyTorch. After we download, extract and organize the HMDB51 video clip files, we proceed to use the inbuilt HMDB51 dataset module as a wrapper for loading the dataset by specifying the location of data and train/test splits.
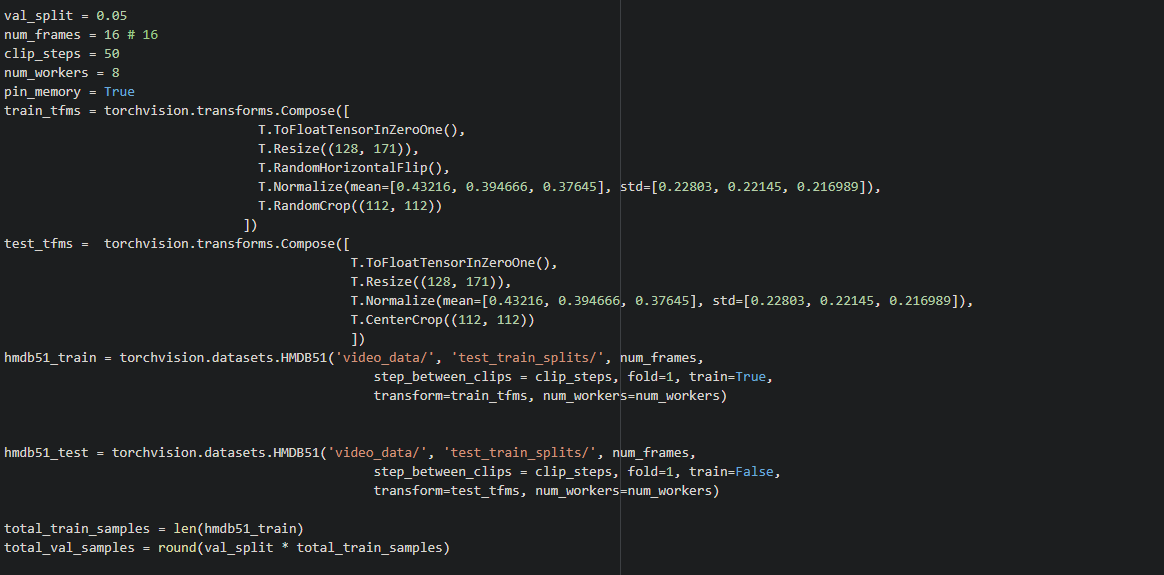
Once we specify the requirements to torchvision.datasets.HMDB51 module, we can easily create a DataLoader for loading the video clips (stack of video frames) in batches using —

And finally, we can start training the custom deep neural net based on Res3D_18 and observe losses and evaluate on the test dataset. HMDB51 splits provided are only for train and test. Ideally, one should randomly split a small percentage of train data for validation during training to gauge the model performance.
We have seen how a simple action recognition/video classification architecture can be set up using PyTorch and also checked the HMDB51 video dataset. As a next step, one should try to plug in I3D architecture and see how the model performance improves. There are a plethora of research papers on I3D and each one of them focusses on extending I3D for some downstream tasks. There are other video datasets that are much bigger in size than HMDB51 and provides activities with different levels of complexities. Action recognition or video classification, in general, transcends to a wide variety of use-cases such as Crowd Monitoring, Customer Behavior Analysis, Theft Prevention, the opportunities are unlimited.
References
-
https://serre-lab.clps.brown.edu/resource/hmdb-a-large-human-motion-database/
-
Colab Notebook https://colab.research.google.com/drive/1jBYVoNxl8zfDeAqElVu5zVFXdThzBy3Q
